Google Workspace Marketplace

TableQA
For TableQA™, TableQA™ helps you answer questions about selected data in google sheets. It's powered by GPT-4, ChatGPT, TAPEX-Large AI, TAPAS-Large AI.
Listing updated:February 5, 2024
Works with:
313





Overview
New Update, Try!
=QA("H2:J5","What is the number of reigns for Harley Race?")
=EARNMONEY("How to earn money from stock")
=MAKEMONEY("How to make money from BTC?")
=SAVEMONEY("how to save money from shopping")
=FINANCEQA("BTC history from 2023-12-01 to 2024-01-01")
=STOCKQA("Query apple stock price today?")
=BETQA("Today U.S. horse race rankings?")
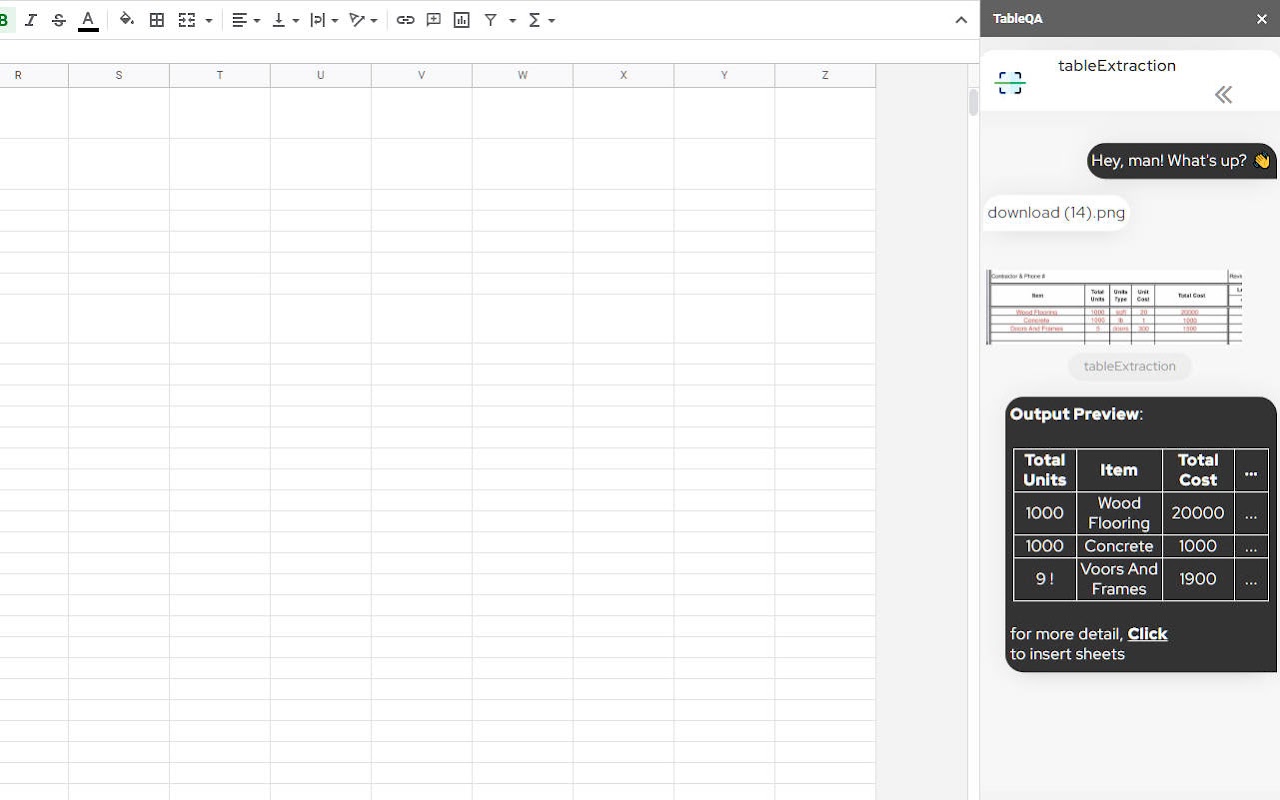
In Google sheets™, TableQA™ add-on is a good tool. Its functions include but are not limited to: providing table Q&A, converting natural language questions to QUERY statements(powered by openai chatgpt), invoice Q&A, extracting table data from pictures (similar to OCR function).
It is powered by a state-of-the-art Microsoft Table-Question-Answer AI & Google Table-Question-Answer AI, These are:
openai GPT-4 AI model.
openai chatgpt AI model.
Microsoft tapex-large-finetuned-wtq AI
Microsoft table-transformer-detection AI
Microsoft table-transformer-structure-recognition AI
Google tapas-large-finetuned-wtq AI
Google tapas-large-finetuned-wikisql-supervised AI
These AIs can achieve more than 50% Dev Accuracy in the benchmark test.
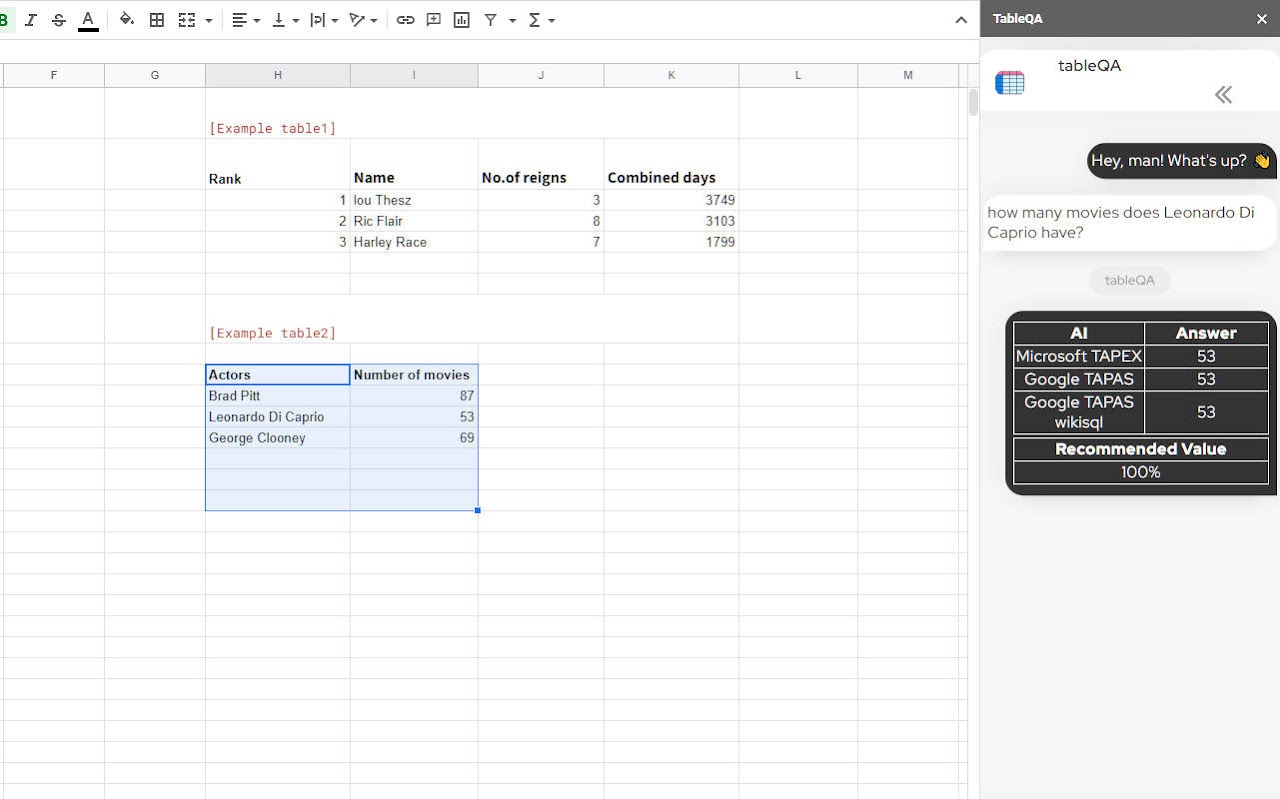
These two AIs are designed to answer questions about tabular data. Don't worry if you don't know how to use SQL, you can ask questions in natural language (preferably English), such as: "how many movies does Leonardo Di Caprio have?", they will understand.
If you are not very confident in AI's answer, you can compare the answers given by Microsoft Table-Question-Answer AI and Google Table-Question-Answer AI respectively. If the answers given by them are consistent, then the result has a high credibility. In the future, many more features will be released!
TableQA™ Guide
Select the sheets data, enter your question, and get the answer from AI.
Detail
[Example table1]:
TableQA Example tables
[Example question1]:
What is the number of reigns for Harley Race?
[Example AI answer]:
microsoft AI answer:
7
google AI answer:
7
[Example table2]:
TableQA Example tables
[Example question2]:
how many movies does Leonardo Di Caprio have?
[Example AI answer]:
microsoft AI answer:
53
google AI answer:
53
AI Model description
TAPAS is a BERT-like transformers model pretrained on a large corpus of English data from Wikipedia in a self-supervised fashion. This means it was pretrained on the raw tables and associated texts only, with no humans labelling them in any way (which is why it can use lots of publicly available data) with an automatic process to generate inputs and labels from those texts. More precisely, it was pretrained with two objectives:
Masked language modeling (MLM): taking a (flattened) table and associated context, the model randomly masks 15% of the words in the input, then runs the entire (partially masked) sequence through the model. The model then has to predict the masked words. This is different from traditional recurrent neural networks (RNNs) that usually see the words one after the other, or from autoregressive models like GPT which internally mask the future tokens. It allows the model to learn a bidirectional representation of a table and associated text.
Intermediate pre-training: to encourage numerical reasoning on tables, the authors additionally pre-trained the model by creating a balanced dataset of millions of syntactically created training examples. Here, the model must predict (classify) whether a sentence is supported or refuted by the contents of a table. The training examples are created based on synthetic as well as counterfactual statements.
This way, the model learns an inner representation of the English language used in tables and associated texts, which can then be used to extract features useful for downstream tasks such as answering questions about a table, or determining whether a sentence is entailed or refuted by the contents of a table. Fine-tuning is done by adding a cell selection head and aggregation head on top of the pre-trained model, and then jointly train these randomly initialized classification heads with the base model on SQa, WikiSQL and finally WTQ.Additional information
sell
PricingFree of charge
code
Developer
Non-trader
email
Support
lock
Privacy policy
description
Terms of service
flag
ReportFlag as inappropriate




Search
Clear search
Close search
Google apps
Main menu