Using neural machine translation to correct grammatical faux pas in Google Docs
Shankar Kumar
Research Scientist
Simon Tong
Principal Engineer
We’re making a significant improvement to how we correct language errors by using Neural Grammar Correction in Docs.
Try Google Workspace at No Cost
Get a business email, all the storage you need, video conferencing, and more.
SIGN UPFirst impressions are everything in the workplace, and these often take place in the documents or presentations that we share with others. Spelling or grammatical errors can be distracting and make a proposal look unprofessional—something we all want to avoid. We’re focused on providing more assistive writing capabilities in G Suite to help you put your best work forward, which is why earlier this year we introduced new grammar correction tools in Google Docs to help people write more quickly and accurately. With the help of machine learning, already more than 100 million grammar suggestions are flagged each week.
Advancing grammar suggestions using neural machine translation
To date, Google’s grammar correction system uses machine translation technology. Essentially each suggestion is treated like a translation task--in this case, translating from the language of 'incorrect grammar' to the language of 'correct grammar.' At a basic level, machine translation performs substitution and reorders words from a source language to a target language, for example, substituting a “source” word in English (“hello”) for a “target” word in Spanish (“hola”).
With the latest advancements from our research team in the area of language understanding--made possible by neural machine translation--soon, we’re making a significant improvement to how we correct language errors by using Neural Grammar Correction in Docs.
How it works
Since Grammatical Error Correction (GEC) can be viewed as "translation" from ungrammatical to grammatical sentences, sequence-to-sequence models developed for neural machine translation can be applied to this task. To train high quality models, we generally want to have millions or billions of examples of parallel data, where each training example consists of a sentence in the source language paired with its translation in the target language. Unlike several other machine translation tasks (such as translating from English to French), there is very little parallel data for GEC. To overcome this challenge, we developed two contrasting methods to generate large quantities of parallel data for GEC:
The first method takes good sentences and makes them worse by automatically translating them to some other language and then back to English.
The second method extracts source-target pairs from Wikipedia edit histories with a minimal amount of filtration.
You can read more about GEC and some of our approaches in this paper.
To ensure that the models were feasible to deploy on Google Docs without using an unreasonable amount of computing resources, we used Tensor Processing Units (TPUs). TPUs have provided substantial performance increases for many other Google products, including Smart Compose in Gmail. In addition, we used Google’s open source Lingvo TensorFlow library, which enabled us to easily experiment with modeling changes, and also allowed us to carefully optimize how the TPU cores generate suggestions.
What this means for writers
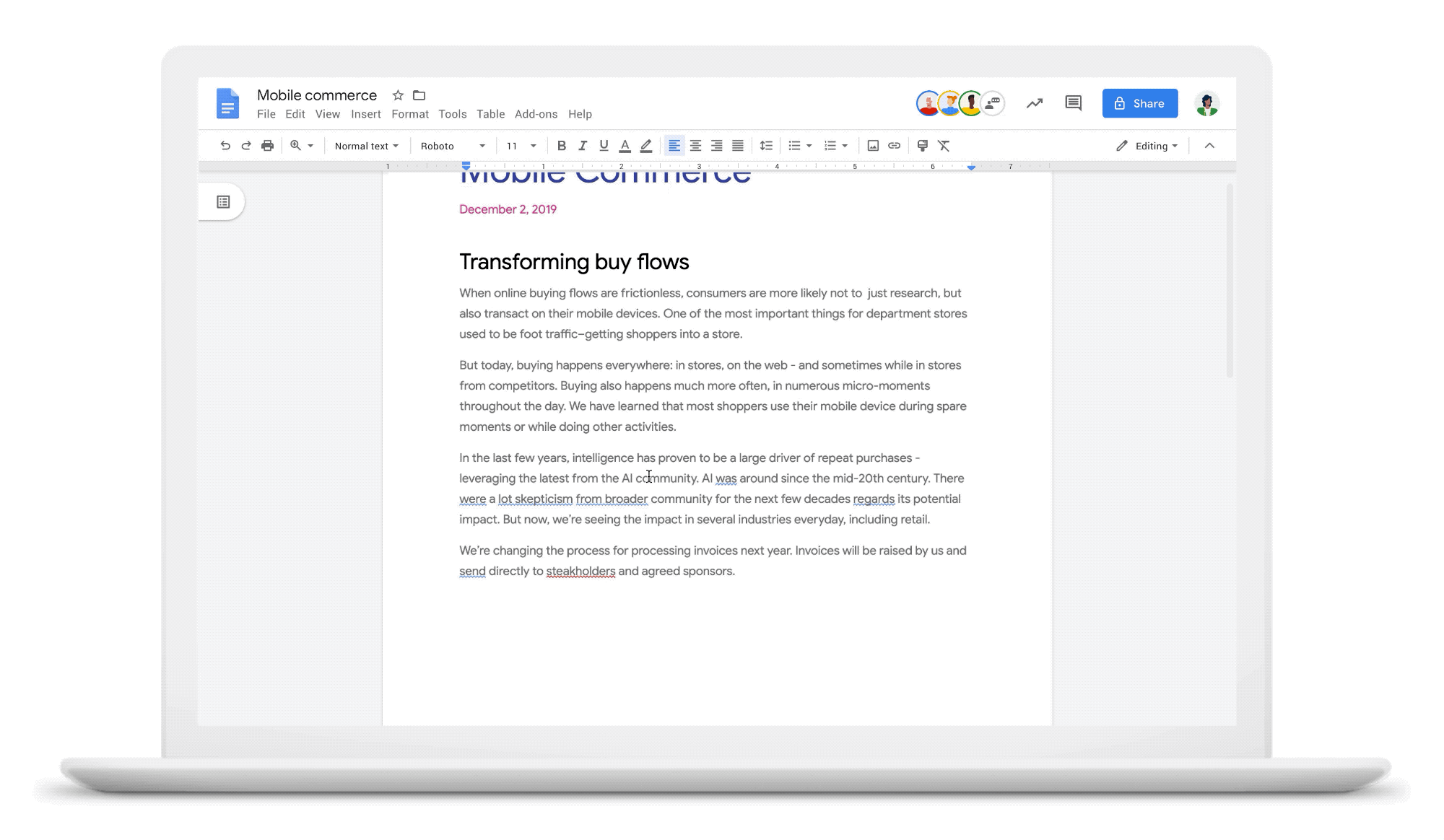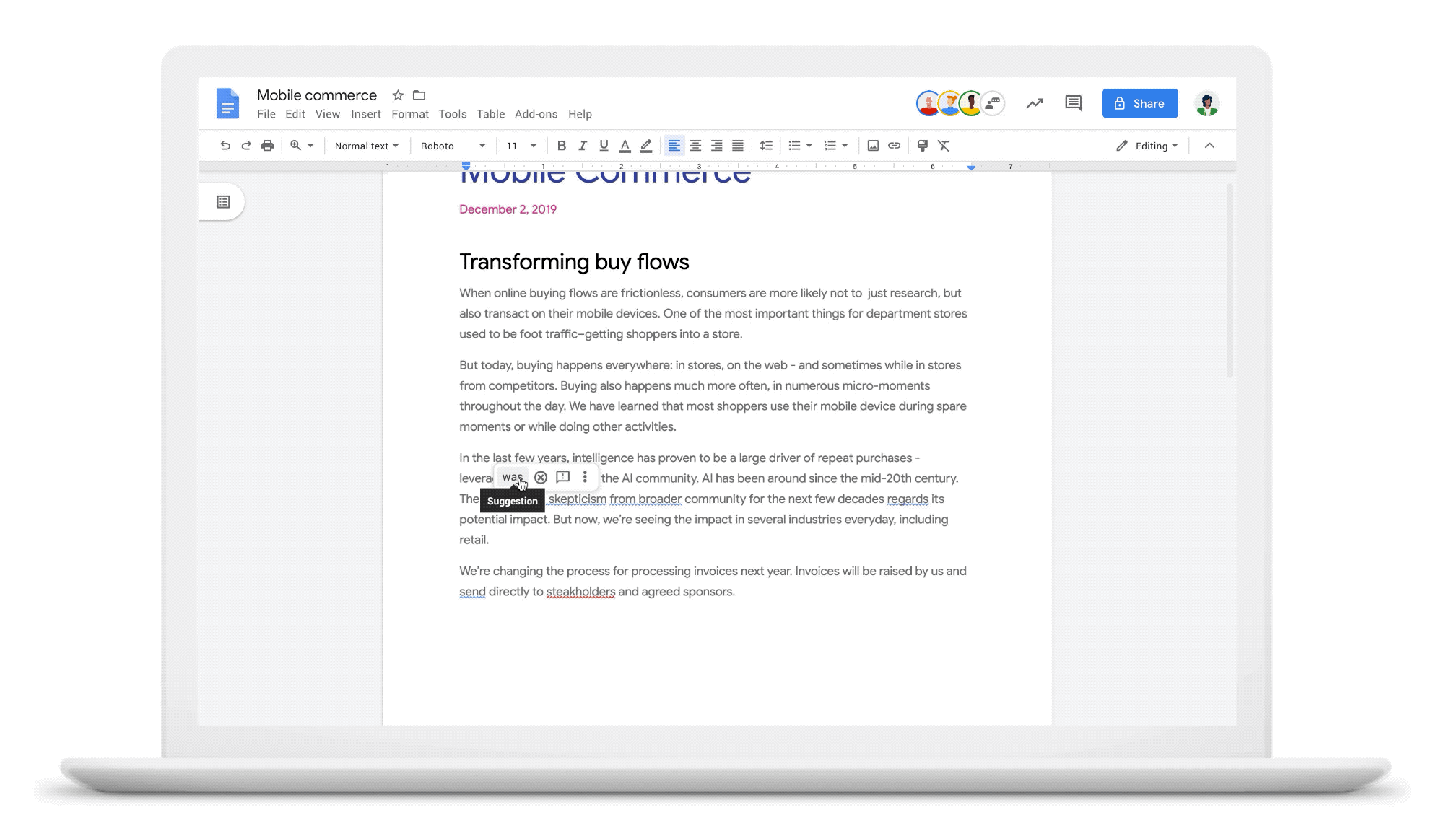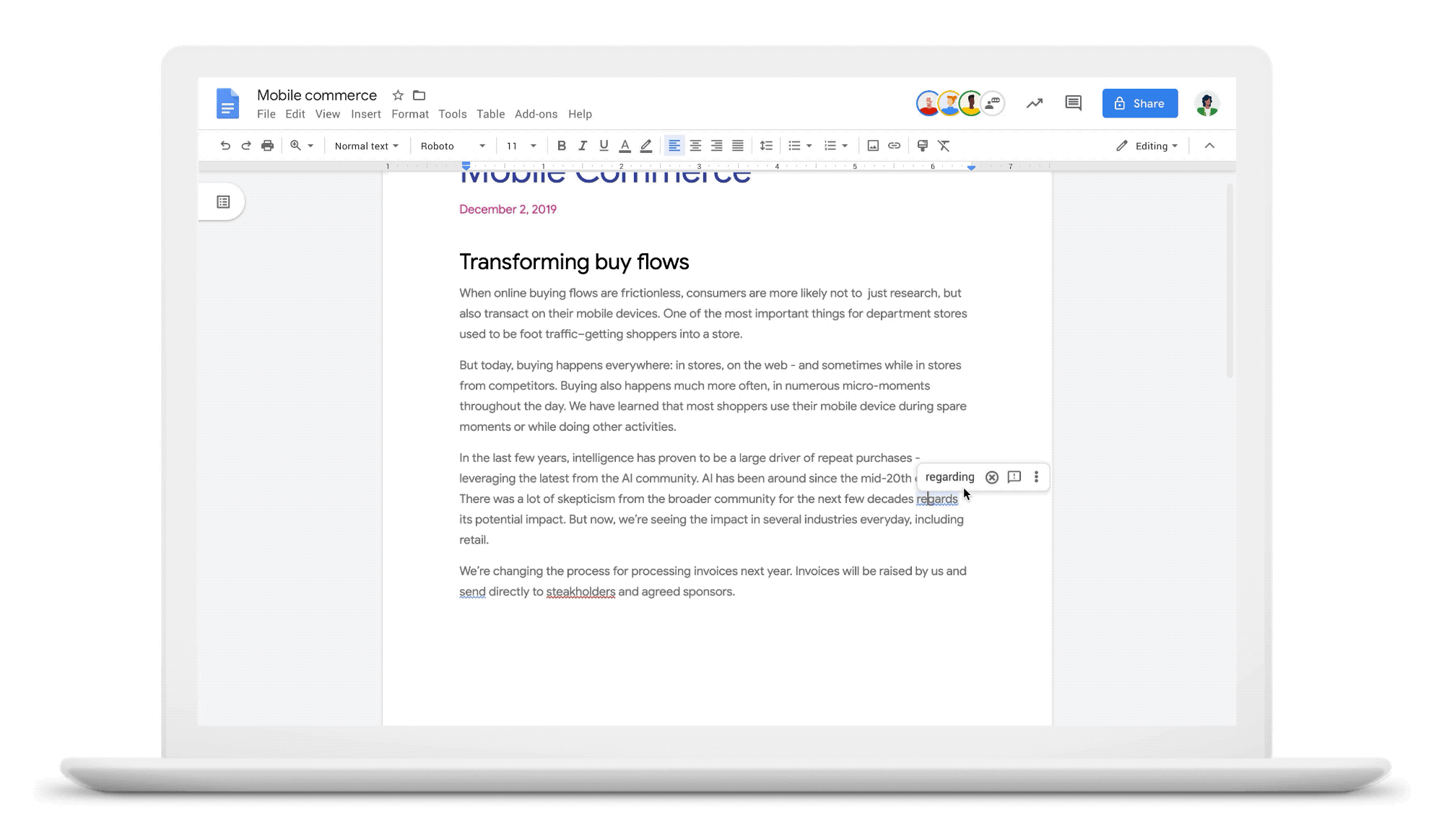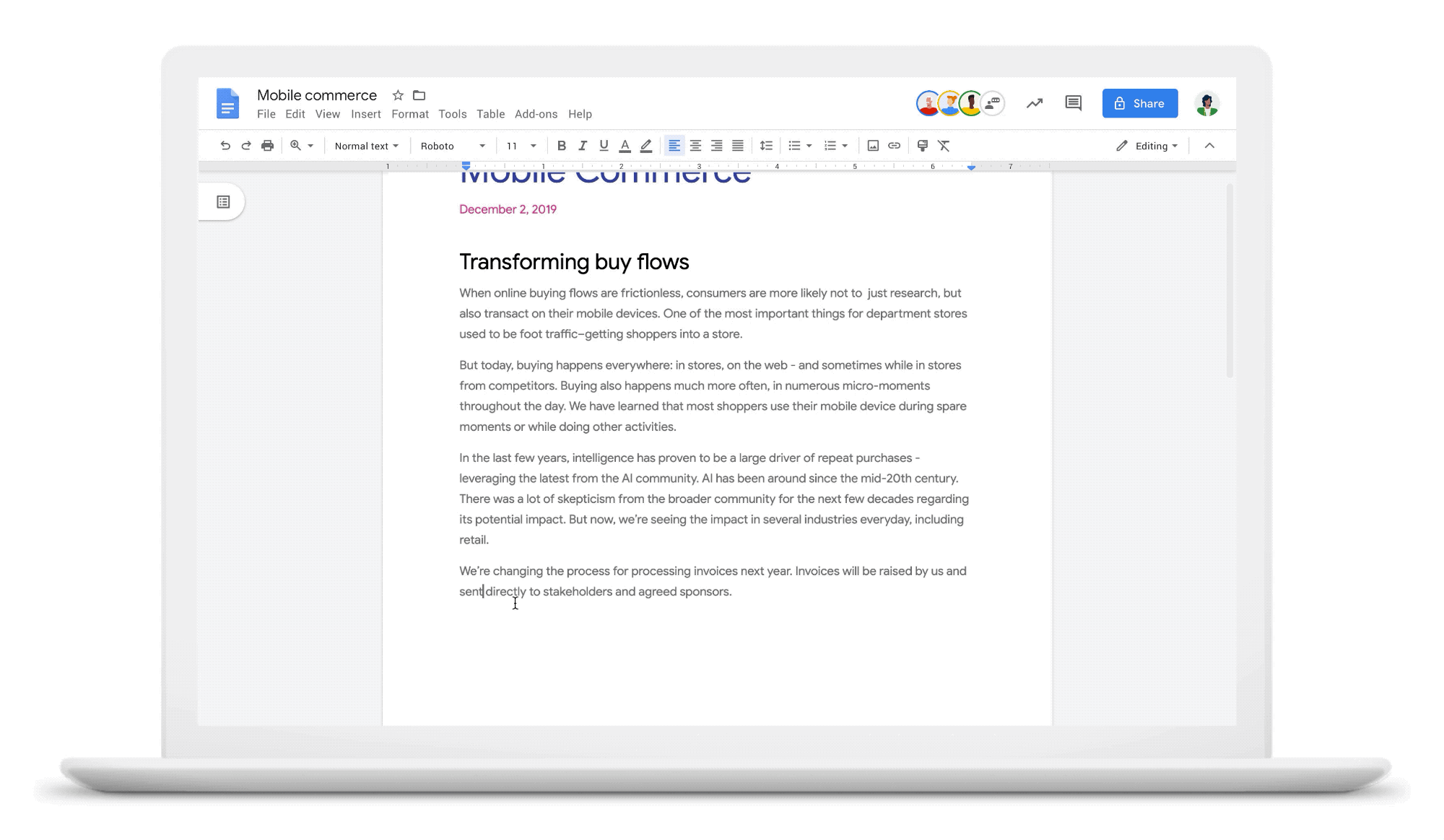
So what does it all mean for you? Well, by applying neural machine translation models to grammar correction, we are able to correct many more of the grammar mistakes you may make while writing. To launch these improvements, we did a lot of testing to ensure that the changes actually are more helpful. Here are some of the examples from our evaluation process that demonstrate neural grammar correction’s capabilities:
What tense is it anyway?

Is it steak or stake?

Changing to the neural machine translation method gives a marked increase in the recall of grammar correction suggestions in Docs. We hope this update can continue to help you write with ease.